

Introduction
Distributed tracing is a technique used to monitor and profile applications in complex, distributed systems. It involves tracking and recording the flow of requests as they traverse across multiple microservices or components. By capturing timing and context information at each step, distributed tracing enables developers and operators to understand the behavior and performance of their systems.
In microservices architectures, where applications are composed of multiple loosely coupled services, distributed tracing plays a crucial role in several ways:
Performance Monitoring
Troubleshooting and Root Cause Analysis
Service Dependencies and Impact Analysis
Load Distribution and Resource Optimization
Performance Baseline and Continuous Improvement
Now, let's delve into the fundamental concepts of distributed tracing and explore how it empowers us to gain deep insights into the behavior and performance of interconnected microservices.
Basic Concepts of Distributed Tracing
Each service in the system is instrumented to generate trace data. This usually involves adding code to create and propagate trace context across service boundaries. Commonly used frameworks and libraries provide built-in support for distributed tracing. Let's break down the hierarchy of distributed tracing to understand it better:
Trace: A trace represents the end-to-end path of a single request as it flows through various services. It is identified by a unique trace ID. Think of it as a tree structure that captures the entire journey of a request.
Span: A span represents an individual operation or action within a service. It represents a specific unit of work and contains information about the start and end times, duration, and any associated metadata. Spans are organized in a hierarchical manner within a trace, forming a parent-child relationship.
Parent Span and Child Span: Within a trace, spans are organized in a parent-child relationship. A parent span initiates a request and triggers subsequent operations, while child spans represent operations that are triggered by the parent span. This hierarchy helps visualize the flow and dependencies between different operations.
Trace Context: Trace context refers to the information that is propagated between services to maintain the trace's continuity. It includes the trace ID, which uniquely identifies the trace, and other contextual information like the parent span ID. Trace context ensures that each service can link its spans to the correct trace and maintain the overall trace structure.
To illustrate this hierarchy, consider a scenario where a user makes a request to a microservices-based application. The request flows through multiple services to fulfill the user's request. Here's how the hierarchy could look:
Trace (Trace ID: 123456)
Span 1 (Service A): Represents an operation in Service A
Span 2 (Service B): Represents an operation triggered by Service A
- Span 3 (Service C): Represents an operation triggered by Service B
Span 4 (Service D): Represents another operation triggered by Service A
- Span 5 (Service E): Represents an operation triggered by Service D
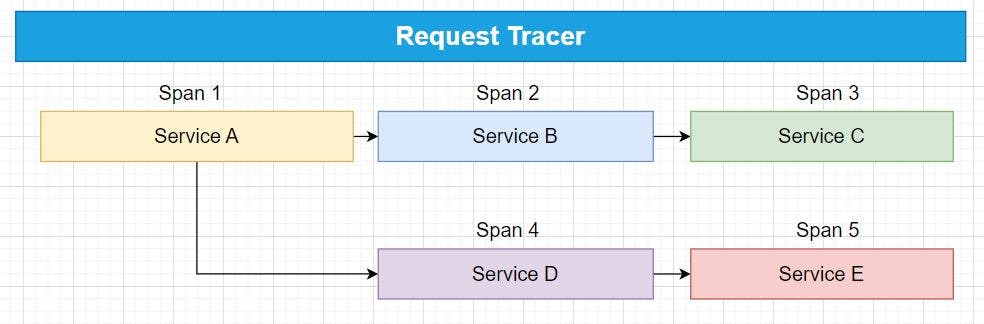
In this example, Trace 123456 captures the entire journey of the user request. Service A initiates the request and triggers Span 1. Span 1 then triggers operations in Service B (Span 2) and Service D (Span 4), each creating their own child spans. Service B triggers an operation in Service C (Span 3), and Service D triggers an operation in Service E (Span 5).
The hierarchy allows you to understand the relationship between different spans and how the request flows through the various services.
I hope this clarifies the hierarchy of distributed tracing for you.
Implementing Distributed Tracing
When comparing tracing frameworks or libraries for implementing distributed tracing in microservices, several popular options are available. Here is a brief list of some widely used frameworks:
OpenTelemetry is a vendor-neutral observability framework that provides support for distributed tracing, metrics, and logs.
Jaeger is an open-source end-to-end distributed tracing system inspired by Google's Dapper and OpenZipkin.
Zipkin is an open-source distributed tracing system initially developed by Twitter.
AWS X-Ray is a distributed tracing service provided by Amazon Web Services.
AppDynamics offers powerful analytics and correlation features, making it suitable for complex microservices architectures.
When comparing these frameworks, consider factors such as language support, integration capabilities, scalability, ease of use, community support, and compatibility with your infrastructure and tooling stack. It is recommended to evaluate these frameworks based on your specific requirements, architectural considerations, and the level of observability and analysis you aim to achieve in your microservices environment.
Here's a small coding example in Node.js using the OpenTelemetry library for instrumenting an Express web application with distributed tracing:
const express = require('express');
const { NodeTracerProvider } = require('@opentelemetry/node');
const { BatchSpanProcessor } = require('@opentelemetry/tracing');
const { JaegerExporter } = require('@opentelemetry/exporter-jaeger');
const { registerInstrumentations } = require('@opentelemetry/instrumentation');
const { HttpInstrumentation } = require('@opentelemetry/instrumentation-http');
// Configure the tracer provider with Jaeger exporter
const tracerProvider = new NodeTracerProvider();
const jaegerExporter = new JaegerExporter({ serviceName: 'my-service', host: 'localhost', port: 6831 });
tracerProvider.addSpanProcessor(new BatchSpanProcessor(jaegerExporter));
tracerProvider.register();
// Initialize Express application
const app = express();
registerInstrumentations({
tracerProvider,
instrumentations: [new HttpInstrumentation()],
});
// Define a route
app.get('/', (req, res) => {
// Create a span to represent the request processing
const span = tracerProvider.getTracer('express-example').startSpan('hello');
// Perform some operations within the span
span.setAttribute('custom.attribute', 'example');
span.addEvent('Processing started', { status: 'info' });
// Business logic goes here...
span.end();
res.send('Hello, World!');
});
// Run the Express application
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
In this example, we start by importing the necessary modules from the OpenTelemetry library. We configure the tracer provider with a Jaeger exporter to send the trace data to a Jaeger backend for storage and visualization.
Next, we initialize an Express application and register the necessary instrumentations using the registerInstrumentations function provided by OpenTelemetry. This automatically instruments the application to capture trace data for incoming requests, including HTTP instrumentation for tracing HTTP requests.
We define a route handler for the root path ("/") and wrap the request processing logic inside a span. We set attributes and add events to the span to provide additional context and information. The business logic of the application can be implemented within this span.
Finally, we start the Express application and listen on port 3000. The instrumented route will automatically generate and propagate trace context, allowing for distributed tracing across services.
Automatic vs Manual Instrumentation
Automatic instrumentation in distributed tracing offers the advantage of ease and convenience. It automatically captures essential trace data without requiring developers to modify their code explicitly. This approach is beneficial for quickly getting started with distributed tracing and for applications with a large codebase. However, it may lack fine-grained control and may not capture all relevant information.
On the other hand, manual instrumentation provides greater flexibility and control. Developers can explicitly define spans, add custom metadata, and instrument specific areas of interest. This approach offers more detailed insights and allows for fine-tuning of tracing behavior. However, manual instrumentation requires additional effort and can be time-consuming, especially for complex applications.
Choosing the suitable approach depends on the specific requirements and trade-offs. Automatic instrumentation is suitable for rapid adoption and simple applications, while manual instrumentation is preferred for more complex scenarios where granular control and detailed insights are crucial. A hybrid approach, combining both methods, can also be employed to strike a balance between convenience and customization.
Trace Visualization and Analysis
Trace visualization tools and dashboards aid in effectively analyzing and interpreting trace data in distributed tracing. They offer the following benefits:
End-to-End Trace Visualization: Provides a graphical representation of request flows, enabling developers to understand the complete journey of a request.
Time-based Analysis: Offers a timeline view to identify bottlenecks, latency issues, and long-running operations affecting performance.
Dependency Mapping: Presents a visual representation of service dependencies, helping identify critical services and their impact on others.
Trace Filtering and Search: Allows developers to focus on specific requests or spans based on criteria like operation name or error status.
Metrics Integration: Correlates trace data with performance metrics for deeper insights into resource utilization and error rates.
Error and Exception Analysis: Highlights errors and exceptions within traces, aiding in root cause analysis.
Alerting and Anomaly Detection: This enables setting up custom alerts for performance issues or deviations from expected behavior.
By leveraging these tools, developers gain a comprehensive understanding of their system's behavior, optimize performance, troubleshoot issues, and make informed decisions for their microservices architecture.
Challenges associated with identifying performance bottlenecks and latency issues using distributed traces:
Large trace volumes: Use sampling techniques to reduce data volume while capturing representative traces.
Distributed nature of traces: Employ distributed context propagation to track requests across services.
Asynchronous communication: Instrument message brokers and event systems to capture asynchronous message correlations.
Data aggregation and analysis: Utilize centralized log management and trace aggregation systems for consolidation and analysis.
Performance impact of instrumentation: Choose lightweight instrumentation libraries and optimize instrumentation implementation.
Diverse technology stack: Ensure compatibility and availability of tracing libraries across different technology stacks.
Techniques to overcome these challenges:
Proactive monitoring and alerting: Implement real-time systems to identify and address performance issues promptly.
Performance profiling and optimization: Utilize profiling tools to optimize performance within services.
Distributed tracing standards and best practices: Adhere to trace context propagation and tracing conventions.
Collaborative troubleshooting: Foster collaboration among teams and utilize cross-functional dashboards and shared trace data.
Use Cases and Real-World Examples of Distributed Tracing in Microservices Architectures
Distributed tracing has proven to be instrumental in helping organizations improve performance, scalability, and fault tolerance in their distributed systems. Here are specific examples highlighting measurable results:
Performance Improvement:
- A social media platform utilized distributed tracing to identify and optimize performance bottlenecks. By analyzing trace data, they discovered that a specific microservice responsible for generating user feeds was causing high latency. After optimizing the service and implementing caching strategies based on trace insights, they achieved a 30% reduction in response times, resulting in improved user experience and increased user engagement.
Scalability Enhancement:
- An e-commerce company leveraged distributed tracing to scale their system during peak traffic periods. By analyzing trace data, they identified services experiencing high loads and optimized resource allocation. With this information, they scaled the infrastructure dynamically and implemented load balancing techniques based on trace insights. As a result, they achieved a 50% increase in concurrent user capacity and maintained optimal system performance even during high traffic events.
Fault Tolerance and Resilience:
- A banking institution implemented distributed tracing to improve fault tolerance in their payment processing system. By analyzing trace data, they identified critical failure points and implemented circuit breaker patterns and retry mechanisms based on trace insights. This resulted in a significant reduction in failed transactions, with a 70% decrease in payment processing errors, leading to improved customer satisfaction and reliability.
Failure Root Cause Analysis:
- A cloud-based SaaS provider used distributed tracing to troubleshoot performance issues. When customers reported slow response times, they examined trace data to identify the root cause. By analyzing spans associated with the slow requests, they discovered a dependency on an external service causing delays. With this insight, they reconfigured their service interactions and implemented fallback strategies, resulting in a 40% reduction in average response times and improved service reliability.
These examples demonstrate how distributed tracing enables organizations to identify performance bottlenecks, optimize resource allocation, enhance scalability, improve fault tolerance, and troubleshoot issues effectively. The measurable results include reduced response times, increased capacity, decreased errors, and enhanced customer satisfaction, highlighting the tangible benefits of distributed tracing in optimizing distributed systems.
Conclusion
Distributed tracing in microservices provides key concepts and benefits. Understanding the basics and implementing it effectively helps optimize performance, troubleshoot errors, and allocate resources efficiently. Trace visualization and analysis tools aid in analyzing trace data. Real-world examples showcase its practical applications, such as improved order processing, enhanced payment reliability, and proactive performance management. Overall, distributed tracing is crucial for understanding system behavior, identifying issues, and making informed decisions for a robust microservices architecture. Some Popular SAAS companies providing easy integration of this feature are Datadog, New Relic, Dynatrace